따라하며 배우는 C++ 19. 모던 C++ 필수 요소들
19.1 람다 함수와 std::function, std::bind, for_each
#include <iostream>
#include <vector>
#include <algorithm>
#include <functional>
using namespace std;
void goodbye(const string& s)
{
cout << "Goodbye " << s << endl;
}
class Object
{
public:
void hello(const string& s)
{
cout << "Hello " << s << endl;
}
};
int main()
{
//lambda-introducer
//lambda-parameter-declaration
//lambda-return-type-clause
//compound-statement
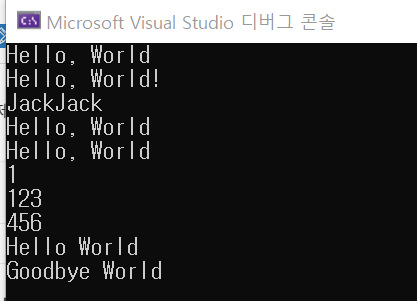
auto func = [](const int& i)->void {cout << "Hello, World" << endl; };
//[]를 lambda-introducer라고 부름
//일반적인 함수처럼 parameter를 정의할 수 있고,
//return type을 ->를 써서 뒤에 표기함.
func(123);
[](const int& i) -> void { cout << "Hello, World!" << endl; }(1234);
//잡다하게 함수 구현할 경우, 람다 함수를 쓰면 간편해진다.
//특히 GUI일 경우
{
string name = "JackJack";
[&]() {std::cout << name << endl; }();
//블록 안에서 &를 쓰면 블록 안의 변수를 가져온다.
//[&name] 도 가능.
//[this]하면 클래스의 멤버도 가능
//[=]라고 하면 변수의 값을 복사해서 대입한다.
//scope의 변수를 싹 가져다 쓸 수 있다!
}
vector<int> v;
v.push_back(1);
v.push_back(2);
auto func2 = [](int val) {cout << val << endl; };
for_each(v.begin(), v.end(), func);
//for_each(v.begin(), v.end(), [](int val) {cout << val << endl; });
//사실 이렇게 바로 넣어버리는 것을 선호하긴 한다.
cout << []()->int {return 1; }() << endl;
std::function<void(int)> func3 = func2;
//함수 포인터를 체계화 시켜준 것. <return type(parameter type)>
func3(123);
std::function<void()>func4 = std::bind(func3, 456);
func4(); //parameter에 456을 알아서 넣어준다.
{
Object instance;
auto f = std::bind(&Object::hello, &instance, std::placeholders::_1);
//parameter가 여러 개 있을 때, palceholder를 쓸 수 있다.
//object 내의 함수를 쓰려면 클래스의 인스턴스가 필요하다.
//함수의 포인터, 인스턴스 포인터, 파라미터 플래그를 넣어줌.
//멤버 function을 instance에 bind
f(string("World"));
auto f2 = std::bind(&goodbye, std::placeholders::_1);
f2(string("World"));
}
}
19.2 C++ 17 함수에서 여러 개의 리턴값 반환하기
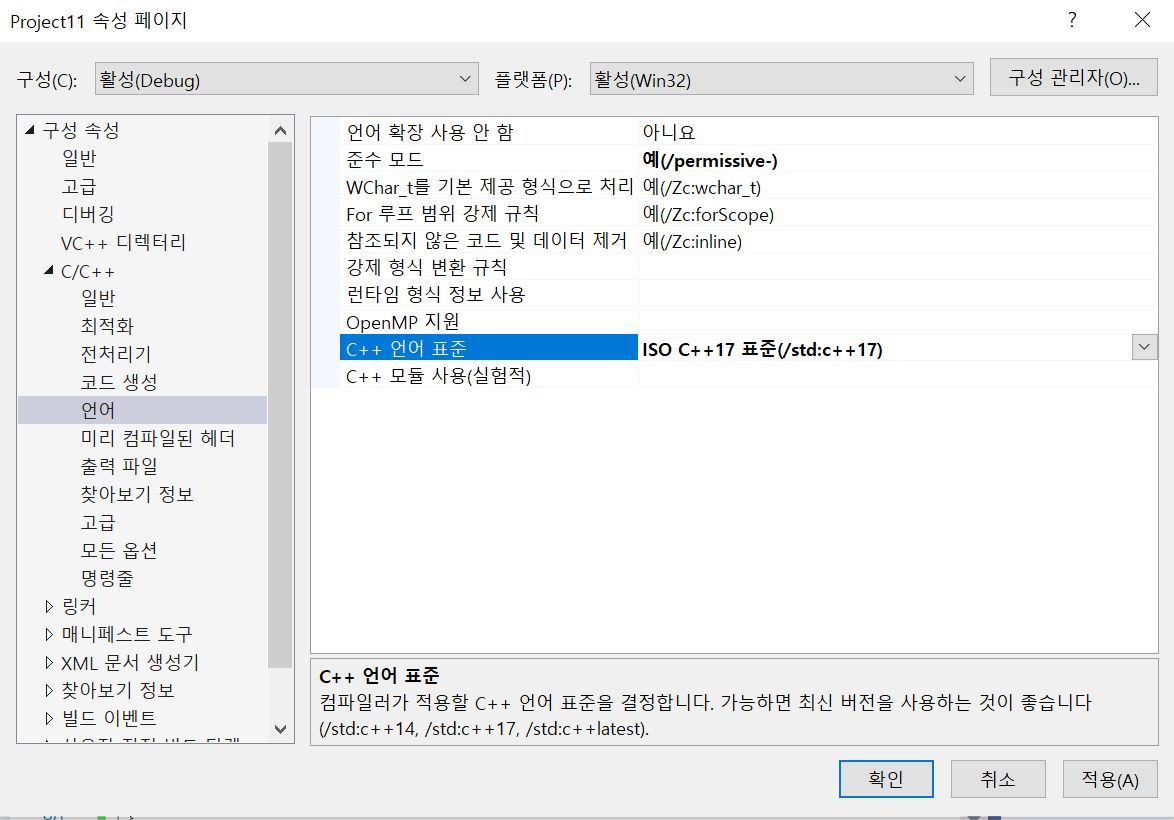
프로젝트 이름 > 속성 > C/C++ > 언어 > C++언어 표준 > 설정
#include <iostream>
#include <tuple>
using namespace std;
tuple<int, int> my_func()
{
return tuple<int, int>(123, 456);
}
int main()
{
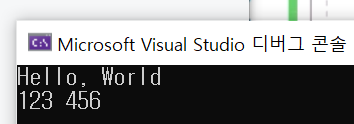
cout << "Hello, World" << endl;
tuple<int, int> result = my_func();
cout << get<0>(result) << " " << get<1>(result) << endl;
return 0;
}
예전에 return 값 여러 개를 받기 위해 tuple을 써서 우회하는 방법.
#include <iostream>
#include <tuple>
using namespace std;
auto my_func()
{
return tuple<int, int>(123, 456);
}
int main()
{
cout << "Hello, World" << endl;
auto result = my_func();
cout << get<0>(result) << " " << get<1>(result) << endl;
return 0;
}
//위의 방법도 가능
아래는 17에서 더 편리해진 방법
#include <iostream>
#include <tuple>
using namespace std;
auto my_func()
{
return tuple(123, 456, 789);
}
int main()
{
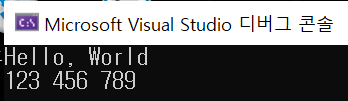
cout << "Hello, World" << endl;
auto [a, b, c] = my_func();
//변수 a b c d를 선언하면서 받는 형태가 될 수 있다.
cout << a << " " << b << " " << c << endl;
return 0;
}
19.3 std thread와 멀티쓰레딩multithreading 기초
프로세스란, OS가 프로그램을 실행시킬 때 관리하는 단위.
하나의 프로세스가 여러 개의 thread를 관리할 수 있다.
여러 개의 core를 동시에 가동하여 효율성을 높이는 방법.
코어가 하나였을 때는 프로세스 하나에 CPU를 여러 개 꽂는 게 더 속도가 안 좋았다.
그래서 멀티쓰레딩 대신 멀티 프로세싱을 하기도 했다.
네트워크를 통해 여러 대의 컴퓨터로 분산 처리를 시도하기도 했다.
분산 처리는 메모리를 공유할 수 없고, 통신을 할 때 부가적인 오버헤드도 있어 비효율적인 면도 있다.
반면에 멀티쓰레드는 메모리를 공유해서 프로그래머를 편하게 만들어주기도 하는 반면,
위험하게 만들기도 한다.
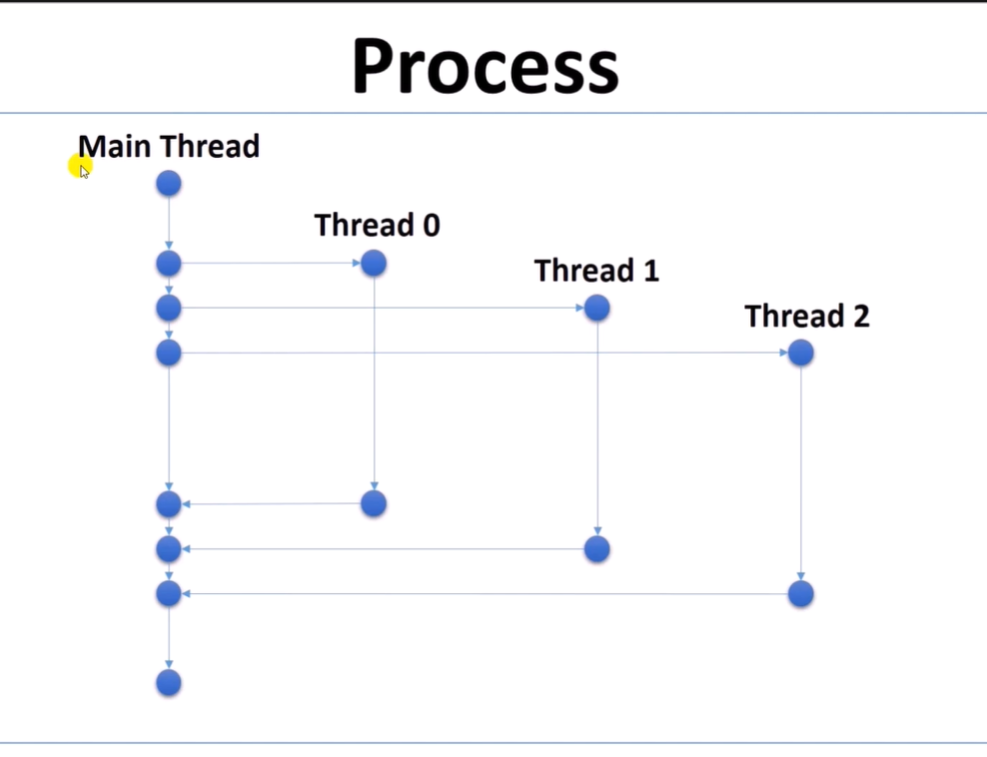
(작업 관리자 창)
보통 물리적 코어의 두 배를 프로세서로 본다.
utilization이 현재 CPU가 가동되는 비율.
#include <iostream>
#include <string>
#include <thread>
#include <chrono>
#include <vector>
#include <mutex>
using namespace std;
int main()
{
const int num_pro = std::thread::hardware_concurrency();
cout << num_pro << endl;
//CPU 코어 개수
cout << std::this_thread::get_id() << endl;
//메인 함수가 실행되고 있는 쓰레드의 아이디.
std::thread t1 = std::thread(
[]()
{
while (true) {}
}
);
return 0;
}
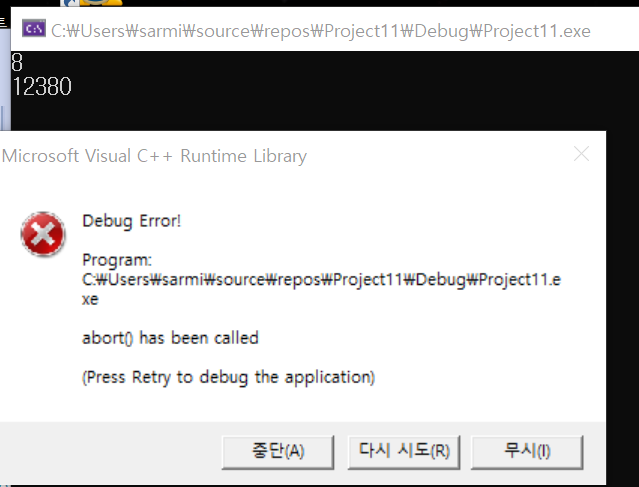
쓰레드가 분기되었는데, 메인 쓰레드가 먼저 끝나서 에러가 생긴 것.
#include <iostream>
#include <string>
#include <thread>
#include <chrono>
#include <vector>
#include <mutex>
using namespace std;
int main()
{
const int num_pro = std::thread::hardware_concurrency();
cout << num_pro << endl;
//CPU 코어 개수
cout << std::this_thread::get_id() << endl;
//메인 함수가 실행되고 있는 쓰레드의 아이디.
std::thread t1 = std::thread(
[]()
{
cout << std::this_thread::get_id() << endl;
while (true) {}
}
);
t1.join(); //t1이 끝날 때까지 기다려준다.
return 0;
}
#include <iostream>
#include <string>
#include <thread>
#include <chrono>
#include <vector>
#include <mutex>
using namespace std;
int main()
{
const int num_pro = std::thread::hardware_concurrency();
cout << num_pro << endl;
//CPU 코어 개수
cout << std::this_thread::get_id() << endl;
//메인 함수가 실행되고 있는 쓰레드의 아이디.
std::thread t1 = std::thread(
[]()
{
cout << std::this_thread::get_id() << endl;
while (true) {}
}
);
std::thread t2 = std::thread(
[]()
{
cout << std::this_thread::get_id() << endl;
while (true) {}
}
);
std::thread t3 = std::thread(
[]()
{
cout << std::this_thread::get_id() << endl;
while (true) {}
}
);
std::thread t4 = std::thread(
[]()
{
cout << std::this_thread::get_id() << endl;
while (true) {}
}
);
t1.join();
t2.join();
t3.join();
t4.join();
return 0;
}이렇게 여러 개의 쓰레드를 돌릴 수 있다.
#include <iostream>
#include <string>
#include <thread>
#include <chrono>
#include <vector>
#include <mutex>
using namespace std;
int main()
{
const int num_pro = std::thread::hardware_concurrency();
cout << num_pro << endl;
//CPU 코어 개수
cout << std::this_thread::get_id() << endl;
//메인 함수가 실행되고 있는 쓰레드의 아이디.
vector<std::thread> my_threads;
my_threads.resize(num_pro);
for (auto& e : my_threads)
e = std::thread([]() {
cout << std::this_thread::get_id() << endl;
while (true) {}});
for (auto& e : my_threads)
e.join();
return 0;
}
#include <iostream>
#include <string>
#include <thread>
#include <chrono>
#include <vector>
#include <mutex>
using namespace std;
int main()
{
auto work_func = [](const string& name)
{
for (int i = 0; i < 5; ++i)
{
std::this_thread::sleep_for(std::chrono::milliseconds(100));
cout << name << " " << std::this_thread::get_id() << " is working " << i << endl;
}
};
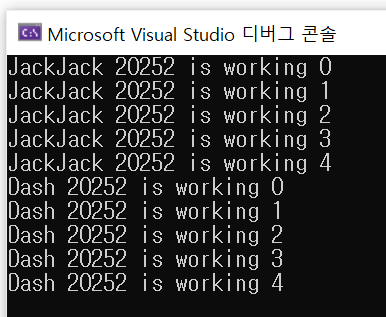
work_func("JackJack");
work_func("Dash");
return 0;
}
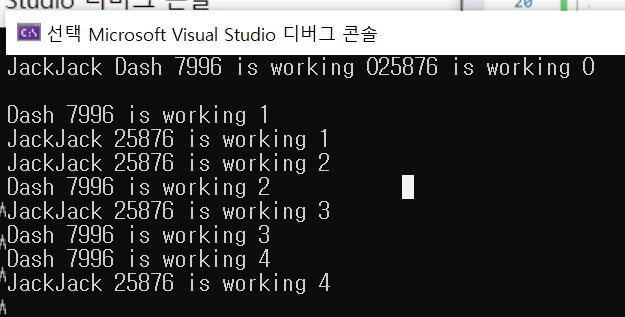
#include <iostream>
#include <string>
#include <thread>
#include <chrono>
#include <vector>
#include <mutex>
using namespace std;
int main()
{
auto work_func = [](const string& name)
{
for (int i = 0; i < 5; ++i)
{
std::this_thread::sleep_for(std::chrono::milliseconds(100));
cout << name << " " << std::this_thread::get_id() << " is working " << i << endl;
}
};
std::thread t1 = std::thread(work_func, "JackJack");
std::thread t2 = std::thread(work_func, "Dash");
t1.join();
t2.join();
return 0;
}
#include <iostream>
#include <string>
#include <thread>
#include <chrono>
#include <vector>
#include <mutex>
using namespace std;
mutex mtx; //mutual exclution의 약자
//독점할 권리를 선언할 수 있다.
int main()
{
auto work_func = [](const string& name)
{
for (int i = 0; i < 5; ++i)
{
std::this_thread::sleep_for(std::chrono::milliseconds(100));
mtx.lock();
cout << name << " " << std::this_thread::get_id() << " is working " << i << endl;
mtx.unlock();
}
};
std::thread t1 = std::thread(work_func, "JackJack");
std::thread t2 = std::thread(work_func, "Dash");
t1.join();
t2.join();
return 0;
}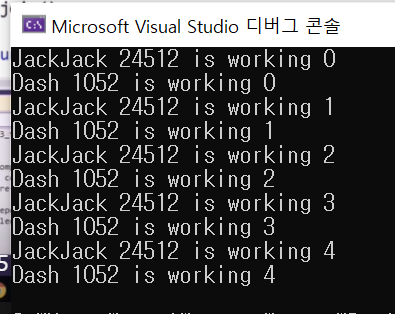
lock을 해 주면 꼭 unlock을 해 주어야 한다.
멀티쓰레딩에서는 기능이 문제가 아니라, 중복되는 기능을 한번에 쓸 때 어떻게 대처해야 하는가가 더 중요하다.
19.4 레이스 컨디션Race condition, std::atomic, std::scoped_lock
#include <iostream>
#include <string>
#include <thread>
#include <chrono>
#include <vector>
#include <mutex>
#include <atomic>
using namespace std;
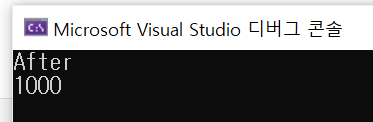
int main()
{
int shared_memory(0);
auto count_func = [&]() {
for (int i = 0; i < 1000; ++i)
{
this_thread::sleep_for(chrono::milliseconds(1));
shared_memory++;
}
};
thread t1 = thread(count_func);
t1.join();
cout << "After" << endl;
cout << shared_memory << endl;
return 0;
}
#include <iostream>
#include <string>
#include <thread>
#include <chrono>
#include <vector>
#include <mutex>
#include <atomic>
using namespace std;
int main()
{
int shared_memory(0);
auto count_func = [&]() {
for (int i = 0; i < 1000; ++i)
{
this_thread::sleep_for(chrono::milliseconds(1));
shared_memory++;
}
};
thread t1 = thread(count_func);
thread t2 = thread(count_func);
t1.join();
t2.join();
cout << "After" << endl;
cout << shared_memory << endl;
return 0;
}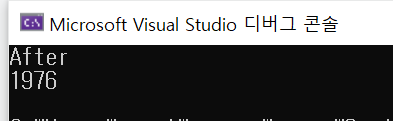
2000이 나와야 하는데, 이상한 숫자가 나온다.
thread1이 shared_memory에 값을 메모리에서 가져와 CPU에서 1을 더해준 다음,
더한 값을 원래 있었던 메모리에 덮어쓴다.
thread1이 shared_memory을 읽어들인 사이에, thread2가 같은 메모리를 똑같이 가져와
덮어쓴다면, 값이 원하는 데로 증가하지 않는다.
<atomic>은 operation이 메모리에서 읽어 오고, 작업을 하고, 다시 저장을 하는
일련의 3단계 작업을 한번에 수행하도록 묶어 버린다.
#include <iostream>
#include <string>
#include <thread>
#include <chrono>
#include <vector>
#include <mutex>
#include <atomic>
using namespace std;
int main()
{
atomic<int> shared_memory(0);
auto count_func = [&]() {
for (int i = 0; i < 1000; ++i)
{
this_thread::sleep_for(chrono::milliseconds(1));
shared_memory++;
}
};
thread t1 = thread(count_func);
thread t2 = thread(count_func);
t1.join();
t2.join();
cout << "After" << endl;
cout << shared_memory << endl;
return 0;
}
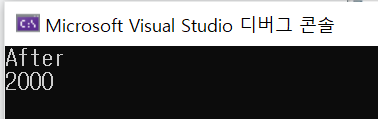
shared_memory.fetch_add(1); //이것으로 사용해도 된다.
그냥 integer를 사용할 때보다 더 느려질 수도 있다.
#include <iostream>
#include <string>
#include <thread>
#include <chrono>
#include <vector>
#include <mutex>
#include <atomic>
using namespace std;
mutex mtx;
int main()
{
int shared_memory(0);
auto count_func = [&]() {
for (int i = 0; i < 1000; ++i)
{
this_thread::sleep_for(chrono::milliseconds(1));
//mtx.lock()
std::lock_guard lock(mtx);
//block안에서 이렇게 선언하여 블록이 끝나면 알아서 unlock을 해 준다.
shared_memory++;
//mtx.unlock();
}
};
thread t1 = thread(count_func);
thread t2 = thread(count_func);
t1.join();
t2.join();
cout << "After" << endl;
cout << shared_memory << endl;
return 0;
}C++17 부터는 std::scoped_lock lock(mtx);이 권장된다.
병렬 처리는 특정 수행이 빠르게 처리될 경우, 오류를 찾기가 힘들다.
19.5 작업 기반 비동기 프로그래밍 aync, future, promise
#include <iostream>
#include <future>
##include <thread>
using namespace std;
int main()
{
//multi-threading
{
int result;
std::thread t([&] {result = 1 + 2; });
t.join();
cout << result << endl;
}
//일반적으론 scope를 잡고, 그 scope의 변수를
//여러 개의 thread들이 공유하는 것이 일반적이다.
//thread 위주로 프로그래밍이 진행된다.
//task-based parallelism
{
//std::future<int> fut = ....
auto fut = std::async([] { return 1 + 2; });
//main thread가 작업하는 것 이외에도 해당 함수 내의 작업을
//멀티쓰레드처럼 동시에 진행한다.
//그 결과를 fut에 받음.
cout << fut.get() << endl;
}
//task-based를 thread-based보다 더 선호한다.
//thread-based는 thread를 생성하고, thread에 어떻게 작업을 분배할 것인가에
//더 중점을 둔다면
//task-based는 어떤 작업을 할 것인가를 위주로 프로그래밍한다.
//return 값을 현재에 바로 받을 수 있다는 보장이 있을 때 쓰인다.
//thread에선 결과값을 받아오는 변수를 thead 밖에서도 접근할 수 있지만
//task-based에선 바로 결과값을 받아오기 때문에 해당 변수가 task와 더욱 밀접하다.
//fut.get()은 fut의 결과값이 있을 때까지 기다릴 수 있다.
//t.join()은 반대로 thread가 끝날 때까지 기다린다!
}
#include <iostream>
#include <future>
##include <thread>
using namespace std;
int main()
{
//future and promise
{
std::promise<int> prom;
auto fut = prom.get_future();
//여기서 아까 예제에선 async로부터 직접 future를 갖고 왔다면
//thread는 결과 값이 아닌 자기 thread를 return하므로,
//future를 받을 수 있는 다른 존재 하나가 필요하기 때문에
//중간에 promise를 거쳐 가는 것이다.
// 이 때 promise에 어떤 값을 넣어주면, future가 발동된다.
auto t = std::thread([](std::promise<int>&& prom)
//promise를 parameter로 넣어줘야 한다.
{
prom.set_value(1 + 2); //promise에 결과 값을 넣어준다.
}, std::move(prom));
//promise가 완수되기를 하염없이 기다린다.
cout << fut.get() << endl; //promise에 넣어준 값이 나온다.
t.join(); //thread는 thread이므로 join 해야 함.
}
}#include <iostream>
#include <future>
##include <thread>
using namespace std;
int main()
{
//future and promise
{
std::promise<int> prom;
auto fut = prom.get_future();
//여기서 아까 예제에선 async로부터 직접 future를 갖고 왔다면
//thread는 결과 값이 아닌 자기 thread를 return하므로,
//future를 받을 수 있는 다른 존재 하나가 필요하기 때문에
//중간에 promise를 거쳐 가는 것이다.
// 이 때 promise에 어떤 값을 넣어주면, future가 발동된다.
auto t = std::async([](std::promise<int>&& prom)
//promise를 parameter로 넣어줘야 한다.
{
prom.set_value(1 + 2); //promise에 결과 값을 넣어준다.
}, std::move(prom));
//promise가 완수되기를 하염없이 기다린다.
cout << fut.get() << endl; //promise에 넣어준 값이 나온다.
}
}async로도 넣을 수 있다.
#include <iostream>
#include <future>
#include <thread>
using namespace std;
int main()
{
{
auto f1 = std::async([] {
cout << "async1 start" << endl;
this_thread::sleep_for(chrono::seconds(2));
cout << "async1 end" << endl;
});
auto f2 = std::async([] {
cout << "async2 start" << endl;
this_thread::sleep_for(chrono::seconds(2));
cout << "async2 end" << endl;
});
cout << "Main function" << endl;
//async는 join이 없어도 문제가 생기지 않는다.
}
}async 예제.
thread와는 내부적으로 처리하는 방식이 좀 다르다.
async는 받아주는 promise가 없을 경우 그냥 sequential로 구동된다.
19.6 멀티쓰레딩 예제(벡터 내적)
Naive한 코드는 다음과 같다.
void dotProductNaive(const vector<int>& v0, const vector<int>& v1,
const unsigned i_start, const unsigned i_end, unsigned long& sum)
{
for (unsigned i = i_start; i < i_end; ++i)
sum += v0[i] * v1[i];
}
//cout << "Naive" <<endl;
{
const auto sta = chrono::steady_clock::now();
unsigned long long sum = 0;
vector<thread> threads; //쓰레드의 벡터
threads.resize(n_threads);
const unsigned n_per_thread = n_data / n_threads; //assumes remainder=0
//thread 생성 중
for (unsigned t = 0; t < n_threads; ++t)
threads[t] = std::thread(dotProductNaive, std::ref(v0), std::ref(v1),
t * n_per_thread, (t + 1) * n_per_thread, std::ref(sum));
for (unsigned t = 0; t < n_threads; ++t)
threads[t].join();
const chrono::duration<double> dur = chrono::steady_clock::now() - sta;
cout << dur.count() << endl;
cout << sum << endl;
cout << endl;
}
Race condition 때문에 제대로 작동하지 않는다.
#include <iostream>
#include <vector>
#include <mutex>
#include <random>
#include <utility>
#include <thread>
#include <atomic>
#include <future>
#include <numeric> // std::innter_product
#include <execution> // parrallen execution
using namespace std;
mutex mtx;
void dotProductNaive(const vector<int>& v0, const vector<int>& v1,
const unsigned i_start, const unsigned i_end, unsigned long& sum)
{
for (unsigned i = i_start; i < i_end; ++i)
sum += v0[i] * v1[i];
}
void dotProductLock(const vector<int>& v0, const vector<int>& v1,
const unsigned i_start, const unsigned i_end, unsigned long long& sum)
{
//cout << "Thread start" << endl;
for (unsigned i = i_start; i < i_end; ++i)
{
std::scoped_lock lock(mtx);
sum += (v0[i] * v1[i]);
}
}
int main()
{
/*
v0 = {1, 2, 3}
v1 = {4, 5, 6}
v0_dot_v1 = 1*4 + 2*5 + 3*6;
*/
const long long n_data = 100'000'000;
const unsigned n_threads = 4;
//initialize vectors
std::vector<int> v0, v1;
v0.reserve(n_data);
v1.reserve(n_data);
random_device seed;
mt19937 engine(seed());
uniform_int_distribution<> uniformDist(1, 10);
for (long long i = 0; i < n_data; ++i)
{
v0.push_back(uniformDist(engine));
v1.push_back(uniformDist(engine));
}
cout << "std::inner_product" << endl;
{
const auto sta = chrono::steady_clock::now();
const auto sum = std::inner_product(v0.begin(), v0.end(), v1.begin(), 0ull);
//0ull --> unsigned long long
const chrono::duration<double> dur = chrono::steady_clock::now() - sta;
cout << dur.count() << endl; //계산된 시간
cout << sum << endl;
cout << endl;
}// 정답도 출력, 퍼포먼스도 출력
{
const auto sta = chrono::steady_clock::now();
unsigned long long sum = 0;
vector<thread> threads;
threads.resize(n_threads);
const unsigned n_per_thread = n_data / n_threads;
for (unsigned t = 0; t < n_threads; ++t)
threads[t] = std::thread(dotProductLock, std::ref(v0), std::ref(v1),
t * n_per_thread, (t + 1) * (n_per_thread), std::ref(sum));
for (unsigned t = 0; t < n_threads; ++t)
threads[t].join();
const chrono::duration <double> dur = chrono::steady_clock::now() - sta;
cout << dur.count() << endl;
cout << sum << endl;
cout << endl;
}
return 0;
}
Race condition이 방지되지만, 느리다.
함수 전체 범위에 lock을 걸면 concurrent하게 실행되는 게 아니라, sequential하게 실행되므로 병렬 처리가 의미 없어진다.
scope_lock은 작은 범위의 블록에 거는 것이 좋지만, 빈번하게 호출되면 퍼포먼스가 오히려 더 떨어질 수도 있다.
#include <iostream>
#include <vector>
#include <mutex>
#include <random>
#include <utility>
#include <thread>
#include <atomic>
#include <future>
#include <numeric> // std::innter_product
#include <execution> // parrallen execution
using namespace std;
mutex mtx;
void dotProductNaive(const vector<int>& v0, const vector<int>& v1,
const unsigned i_start, const unsigned i_end, unsigned long& sum)
{
for (unsigned i = i_start; i < i_end; ++i)
sum += v0[i] * v1[i];
}
void dotProductLock(const vector<int>& v0, const vector<int>& v1,
const unsigned i_start, const unsigned i_end, unsigned long long& sum)
{
//cout << "Thread start" << endl;
for (unsigned i = i_start; i < i_end; ++i)
{
std::scoped_lock lock(mtx);
sum += (v0[i] * v1[i]);
}
}
void dotProductAtomic(const vector<int>& v0, const vector<int>& v1,
const unsigned i_start, const unsigned i_end, atomic<unsigned long long>& sum)
{
for(unsigned i = i_start; i < i_end; ++i)
{
sum += v0[i] * v1[i];
}
}
int main()
{
/*
v0 = {1, 2, 3}
v1 = {4, 5, 6}
v0_dot_v1 = 1*4 + 2*5 + 3*6;
*/
const long long n_data = 100'000'000;
const unsigned n_threads = 4;
//initialize vectors
std::vector<int> v0, v1;
v0.reserve(n_data);
v1.reserve(n_data);
random_device seed;
mt19937 engine(seed());
uniform_int_distribution<> uniformDist(1, 10);
for (long long i = 0; i < n_data; ++i)
{
v0.push_back(uniformDist(engine));
v1.push_back(uniformDist(engine));
}
cout << "std::inner_product" << endl;
{
const auto sta = chrono::steady_clock::now();
const auto sum = std::inner_product(v0.begin(), v0.end(), v1.begin(), 0ull);
//0ull --> unsigned long long
const chrono::duration<double> dur = chrono::steady_clock::now() - sta;
cout << dur.count() << endl; //계산된 시간
cout << sum << endl;
cout << endl;
}// 정답도 출력, 퍼포먼스도 출력
//atomic
cout << "Atomic" << endl;
{
const auto sta = chrono::steady_clock::now();
atomic<unsigned long long> sum = 0;
vector<thread> threads;
threads.resize(n_threads);
const unsigned n_per_thread = n_data / n_threads;
for (unsigned t = 0; t < n_threads; ++t)
threads[5] = std::thread(dotProductAtomic, std::ref(v0), std::ref(v1),
t * n_per_thread, (t + 1) * n_per_thread, std::ref(sum));
for (unsigned t = 0; t < n_threads; ++t)
threads[t].join();
const chrono::duration<double> dur = chrono::steady_clock::now() - sta;
cout << dur.count() << endl;
cout << sum << endl;
cout << endl;
}
return 0;
}Atomic 예제
#include <iostream>
#include <vector>
#include <mutex>
#include <random>
#include <utility>
#include <thread>
#include <atomic>
#include <future>
#include <numeric> // std::innter_product
#include <execution> // parrallen execution
using namespace std;
mutex mtx;
void dotProductNaive(const vector<int>& v0, const vector<int>& v1,
const unsigned i_start, const unsigned i_end, unsigned long& sum)
{
for (unsigned i = i_start; i < i_end; ++i)
sum += v0[i] * v1[i];
}
void dotProductLock(const vector<int>& v0, const vector<int>& v1,
const unsigned i_start, const unsigned i_end, unsigned long long& sum)
{
//cout << "Thread start" << endl;
for (unsigned i = i_start; i < i_end; ++i)
{
std::scoped_lock lock(mtx);
sum += (v0[i] * v1[i]);
}
}
void dotProductAtomic(const vector<int>& v0, const vector<int>& v1,
const unsigned i_start, const unsigned i_end, atomic<unsigned long long>& sum)
{
for(unsigned i = i_start; i < i_end; ++i)
{
sum += v0[i] * v1[i];
}
}
auto dotProductFuture(const vector<int>& v0, const vector<int>& v1,
const unsigned i_start, const unsigned i_end)
{
int sum = 0;
//local sum
for (unsigned i = i_start; i < i_end; ++i)
sum += v0[i] * v1[i];
return sum;
}
int main()
{
/*
v0 = {1, 2, 3}
v1 = {4, 5, 6}
v0_dot_v1 = 1*4 + 2*5 + 3*6;
*/
const long long n_data = 100'000;
const unsigned n_threads = 4;
//initialize vectors
std::vector<int> v0, v1;
v0.reserve(n_data);
v1.reserve(n_data);
random_device seed;
mt19937 engine(seed());
uniform_int_distribution<> uniformDist(1, 10);
for (long long i = 0; i < n_data; ++i)
{
v0.push_back(uniformDist(engine));
v1.push_back(uniformDist(engine));
}
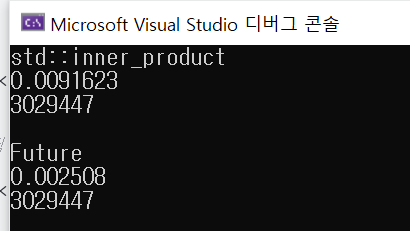
cout << "std::inner_product" << endl;
{
const auto sta = chrono::steady_clock::now();
const auto sum = std::inner_product(v0.begin(), v0.end(), v1.begin(), 0ull);
//0ull --> unsigned long long
const chrono::duration<double> dur = chrono::steady_clock::now() - sta;
cout << dur.count() << endl; //계산된 시간
cout << sum << endl;
cout << endl;
}// 정답도 출력, 퍼포먼스도 출력
cout << "Future" << endl;
{
const auto sta = chrono::steady_clock::now();
unsigned long long sum = 0;
vector<std::future<int>> futures;
futures.resize(n_threads);
const unsigned n_per_thread = n_data / n_threads;
for (unsigned t = 0; t < n_threads; ++t)
futures[t] = std::async(dotProductFuture, std::ref(v0), std::ref(v1),
t * n_per_thread, (t + 1) * n_per_thread);
for (unsigned t = 0; t < n_threads; ++t)
sum += futures[t].get();
const chrono::duration<double> dur = chrono::steady_clock::now() - sta;
cout << dur.count() << endl;
cout << sum << endl;
cout << endl;
}
return 0;
}
task-based
19.7 완벽한 전달Perfect Forwarding과 std::forward
#include <iostream>
#include <vector>
#include <utility> //std::forward
using namespace std;
struct MyStruct
{};
void func(MyStruct& s)
{
cout << "Pass by L-ref" << endl;
}
void func(MyStruct&& s) //오버로딩
{
cout << "Pass by R-ref" << endl;
}
int main()
{
MyStruct(s);
func(s); //l-value
func(MyStruct()); //r-value
}
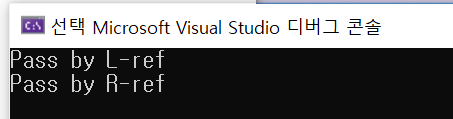
IDE 자체적으로 L-ref, R-ref를 구분해준다!
#include <iostream>
#include <vector>
#include <utility> //std::forward
using namespace std;
struct MyStruct
{};
void func(MyStruct& s)
{
cout << "Pass by L-ref" << endl;
}
void func(MyStruct&& s) //오버로딩
{
cout << "Pass by R-ref" << endl;
}
template<typename T>
void func_wrapper(T t)
{
func(t);
}
int main()
{
MyStruct(s);
func_wrapper(s);
func_wrapper(MyStruct());
return 0;
}
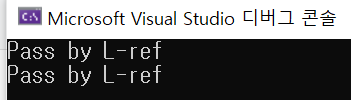
그러나 templatize를 하면 L-value인지, R-value인지 구분할 수 있는 정보가 날라가 버린다.
#include <iostream>
#include <vector>
#include <utility> //std::forward
using namespace std;
struct MyStruct
{};
void func(MyStruct& s)
{
cout << "Pass by L-ref" << endl;
}
void func(MyStruct&& s) //오버로딩
{
cout << "Pass by R-ref" << endl;
}
template<typename T>
void func_wrapper(T&& t)
{
func(std::forward<T>(t));
}
int main()
{
MyStruct(s);
func_wrapper(s);
func_wrapper(MyStruct());
return 0;
}
perfect-forward를 쓰면 위 두개를 구분할 수 있게 된다.
#include <iostream>
#include <vector>
#include <cstdio>
#include <utility>
using namespace std;
class CustomVector
{
public:
unsigned n_data = 0;
int* ptr = nullptr;
CustomVector(const unsigned& _n_data, const int& _init = 0)
{
cout << "Constructor" << endl;
init(_n_data, _init);
}
CustomVector(CustomVector& l_input)
{
cout << "Copy constructor" << endl;
init(l_input.n_data);
for (unsigned i = 0; i < n_data; ++i)
ptr[i] = l_input.ptr[i];
}
CustomVector(CustomVector&& r_input)
{
cout << "Move constructor" << endl;
n_data = r_input.n_data;
ptr = r_input.ptr;
r_input.n_data = 0;
r_input.ptr = nullptr;
}
~CustomVector()
{
delete[] ptr;
}
void init(const unsigned& _n_data, const int& _init = 0)
{
n_data = _n_data;
ptr = new int[n_data];
for (unsigned i = 0; i < n_data; ++i)
ptr[i] = _init;
}
};
int main()
{
CustomVector my_vec(10, 1024);
CustomVector temp(my_vec);
cout << my_vec.n_data << endl;
}
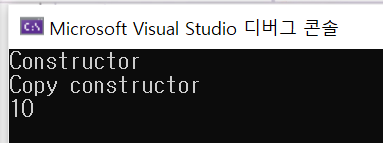
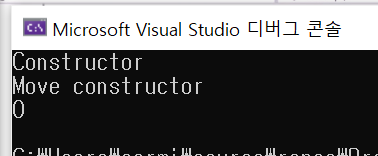
int main()
{
CustomVector my_vec(10, 1024);
CustomVector temp(std::move(my_vec));
cout << my_vec.n_data << endl;
}
#include <iostream>
#include <vector>
#include <cstdio>
#include <utility>
using namespace std;
class CustomVector
{
public:
unsigned n_data = 0;
int* ptr = nullptr;
CustomVector(const unsigned& _n_data, const int& _init = 0)
{
cout << "Constructor" << endl;
init(_n_data, _init);
}
CustomVector(CustomVector& l_input)
{
cout << "Copy constructor" << endl;
init(l_input.n_data);
for (unsigned i = 0; i < n_data; ++i)
ptr[i] = l_input.ptr[i];
}
CustomVector(CustomVector&& r_input)
{
cout << "Move constructor" << endl;
n_data = r_input.n_data;
ptr = r_input.ptr;
r_input.n_data = 0;
r_input.ptr = nullptr;
}
~CustomVector()
{
delete[] ptr;
}
void init(const unsigned& _n_data, const int& _init = 0)
{
n_data = _n_data;
ptr = new int[n_data];
for (unsigned i = 0; i < n_data; ++i)
ptr[i] = _init;
}
};
void doSomething(CustomVector& vec)
{
cout << "Pass by L-reference" << endl;
CustomVector new_vec(vec);
}
void doSomething(CustomVector&& vec)
{
cout << "Pass by R-reference" << endl;
CustomVector new_vec(std::move(vec));
}
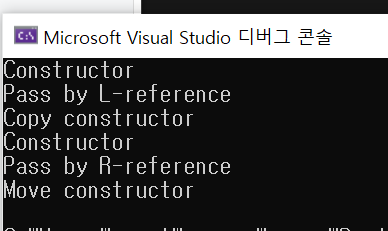
int main()
{
CustomVector my_vec(10, 1024);
doSomething(my_vec);
doSomething(CustomVector(10, 8));
}
#include <iostream>
#include <vector>
#include <cstdio>
#include <utility>
using namespace std;
class CustomVector
{
public:
unsigned n_data = 0;
int* ptr = nullptr;
CustomVector(const unsigned& _n_data, const int& _init = 0)
{
cout << "Constructor" << endl;
init(_n_data, _init);
}
CustomVector(CustomVector& l_input)
{
cout << "Copy constructor" << endl;
init(l_input.n_data);
for (unsigned i = 0; i < n_data; ++i)
ptr[i] = l_input.ptr[i];
}
CustomVector(CustomVector&& r_input)
{
cout << "Move constructor" << endl;
n_data = r_input.n_data;
ptr = r_input.ptr;
r_input.n_data = 0;
r_input.ptr = nullptr;
}
~CustomVector()
{
delete[] ptr;
}
void init(const unsigned& _n_data, const int& _init = 0)
{
n_data = _n_data;
ptr = new int[n_data];
for (unsigned i = 0; i < n_data; ++i)
ptr[i] = _init;
}
};
void doSomething(CustomVector& vec)
{
cout << "Pass by L-reference" << endl;
CustomVector new_vec(vec);
}
void doSomething(CustomVector&& vec)
{
cout << "Pass by R-reference" << endl;
CustomVector new_vec(std::move(vec));
}
template<typename T>
void doSomethingTemplate(T&& vec)
{
doSomething(std::forward<T>(vec));
}
int main()
{
CustomVector my_vec(10, 1024);
doSomethingTemplate(my_vec);
doSomethingTemplate(CustomVector(10, 8));
}
19.8 자료형 추론 auto와 decltype
#include <iostream>
#include <vector>
#include <cstdio>
#include <algorithm>
using namespace std;
class Examples
{
public:
void ex1()
{
std::vector<int> vect;
for (std::vector<int>::iterator itr = vect.begin(); itr != vect.end(); ++itr)
cout << *itr;
for (auto itr = vect.begin(); itr != vect.end(); itr++)
cout << *itr;
for (auto itr : vect) //for (const & itr : vect)
cout << itr;
}
void ex2()
{
int x = int();
auto auto_x = x;
const int& crx = x;
auto auto_crx1 = crx; //auto는 형을 받아들일 때 const를 떼 버린다.
const auto& auto_crx2 = crx; //auto에 const와 &를 받아줘야 한다.
volatile int vx = 1024;
//volatile은 값이 자주 변하기 때문에 최적화할 때 뺴 달라는 말.
auto avx = vx; //여기도 volatile을 떼고 int만 남긴다.
volatile auto vavx = vx;
//auto는 가장 기본적인 것만 변환하고, 자잘한 것은 추가해야 한다.
}
template<class T>
void func_ex3(T arg)
{}
/*template <class T>
void func_ex3(const T& arg)
{}
*/ //이렇게 추가해야 한다.
void ex3()
{
const int& crx = 123;
func_ex3(crx); //여기서 const 와 &를뗴 버린다.
}
void ex4()
{
const int c = 0;
auto& rc = c;
//rc = 123; //error //여기서 const가 여전히 붙어 있다.
//여기서 const int의 reference는 무조건 const가 붙어야 한다(아니면 못 가져옴)
//그래서 이럴 땐 auto가 const를 붙인다.
}
void ex5() //amendment = 개정
{
int i = 42;
auto&& ri_1 = i; //l-value //왼쪽에 l-value가 들어오면 무조건 l-value.
auto&& ri_2 = 42; //r-value
}
void ex6()
{
int x = 42;
const int* p1 = &x;
auto p2 = p1; //const int * 까지 찾아줌.
}
template <typename T, typename S>
void func_ex7(T lhs, S rhs)
{
auto prod1 = lhs * rhs; //곱하기를 한 결과값의 형이 어떻게 되는지 모름!
//typedef typeof(lhs * rhs) product_type; //pre-c++11 'some' compilers
//일부 컴파일러에서 제공해줬음. 즉, 데이터 타입을 리턴해주는 함수가 있었음.
typedef decltype(lhs* rhs) product_type;
//이것이 정식으로 넘어옴. decltype으로.
product_type prod2 = lhs * rhs;
decltype(lhs * rhs) prod3 = lhs * rhs; //자료형처럼 바로 사용할 수 있음.
}
template <typename T, typename S>
auto func_ex8(T lhs, S rhs) -> decltype(lhs* rhs)
{
return lhs * rhs;
}
//decltype(lhs * rhs) func_ex8(T lhs, S rhs)
//는 컴파일러가 읽어들이는 순서 상 읽을 수 없다.
void ex7_8()
{
func_ex7(1.0, 345);
func_ex8(1.2, 345);
}
struct S
{
int m_x;
S()
{
m_x = 42;
}
};
void ex9()
{
int x;
const int cx = 42;
const int& crx = x;
const S* p = new S();
auto a = x;
auto b = cx;
auto c = crx;
auto d = p;
auto e = p->m_x;
//e는 그냥 integer가 된다. p는 const지만 복사해서 상관없어지는 것
typedef decltype(x) x_type; //int
typedef decltype(cx) cx_type; //const int
typedef decltype(crx) crx_type; //const int &
typedef decltype(p->m_x) m_x_type; //int
//멤버는 int로 선언되어 있어서.
//declared type은 선언된 타입 그대로를 다 가져옴.
typedef decltype((x)) x_with_parens_type; //add references to lvalues
typedef decltype((cx)) cx_with_parens_type;
typedef decltype((crx)) crx_with_parens_type;
typedef decltype((p->m_x)) m__with_parens_type;
//reference라 변화가 되면 안된다는 const도 같이 가져옴
}
const S foo()
{
return S();
}
const int& foobar()
{
return 123;
}
void ex10()
{
std::vector<int> vect = { 42, 43 };
auto a = foo(); //S
typedef decltype(foo()) foo_type; //const S
auto b = foobar();
typedef decltype(foobar()) foobar_type;
auto itr = vect.begin();
typedef decltype(vect.begin()) iterator_type;
auto first_element = vect[0];
decltype(vect[1]) second_element = vect[1];
}
void ex11()
{
int x = 0;
int y = 0;
const int cx = 42;
const int cy = 43;
double d1 = 3.14;
double d2 = 2.72;
typedef decltype(x* y) prod_xy_type; //int
auto a = x * y; //int
typedef decltype(cx* cy) prod_cxcy_type; //int
auto a = cx * cy; //in //result is prvalue, 상수이므로 그냥 int
typedef decltype(d1 < d2 ? d1 : d2) cond_type; // l-value에는 &가 붙는다.
auto c = d1 < d2 ? d1 : d2; //그냥 double
typedef decltype(x < d2 ? x : d2) cond_type_mixed; //double로 형변환이 잘 된다.
auto d = x < d2 ? x : d2;
//auto d = std::min(x, dbl); //error, min은 데이터 타입이 같아야 비교해줌.
}
template<typename T, typename S>
auto fpmin_wrong(T x, S y) -> decltype(x < y ? x : y)
{
return x < y ? x : y;
}
//여기서 T와 S의 형이 같으면 reference가 붙는게 단점.
template<typename T, typename S>
auto fpmin(T x, S y) ->
typename std::remove_reference<decltype(x < y ? x : y)>::type
//reference를 제거한 타입을 사용한다.
{
return x < y ? x : y;
}
void ex12()
{
int i = 42;
double d = 45.1;
//auto a = std::min(i, d); //error
auto a = std::min(static_cast<double>(i), d);
int& j = i;
typedef decltype(fpmin_wrong(d, d)) fpmin_return_type1; //double의 reference
typedef decltype(fpmin_wrong(d, d)) fpmin_return_type2; //그냥 double
typedef decltype(fpmin_wrong(d, d)) fpmin_return_type3; //그냥 double
}
void ex13()
{
std::vector<int> vect; //vect is empty
typedef decltype(vect[0]) integer;
//실제 수행은 안해서 문제는 안 생김
}
template<typename R>
class SomeFunctor
{
public:
typedef R result_type;
SomeFunctor()
{
}
result_type operator() ()
{
return R();
}
};
void ex14()
{
SomeFunctor<int> func;
typedef decltype(func)::result_type integer; //nested type;
//함수 안의 nested type도 간편하게 접근 가능.
}
void ex15()
{
auto lambda = []() {return 42; };
decltype(lambda) lambda2(lambda);
decltype((lambda)) lambda3(lambda);
cout << "Lambda functions" << endl;
cout << &lambda << " " << &lambda2 << endl;
cout << &lambda << " " << &lambda3 << endl;
}
void ex16()
{
//generic lambda
auto lambda = [](auto x, auto y)
{
return x + y;
};
cout << lambda(1.1, 2) << " " << lambda(3, 4) << " " << lambda(4.5, 2.2) << endl;
}
};
int main()
{
Examples examples;
examples.ex1();
examples.ex2();
examples.ex3();
examples.ex10();
examples.ex12();
examples.ex14();
examples.ex15();
examples.ex16();
}'개발 공부 > C++' 카테고리의 다른 글
| 따라하며 배우는 C++ 18. 입력과 출력 (0) | 2020.07.03 |
|---|---|
| 따라하며 배우는 C++ 17. string 문자열 클래스 (0) | 2020.07.03 |
| 따라하며 배우는 C++ 16. 표준 템플릿 라이브러리 (0) | 2020.07.03 |
| 따라하며 배우는 C++ 15. 의미론적 이동과 스마트 포인터 (0) | 2020.07.03 |
| 따라하며 배우는 C++ 14. 예외 처리 (0) | 2020.07.02 |



